
変化や不調和が唐突に起こる現代において、真のブレイクスルーは従来の思考パターンを破る「問い」から生まれます。
生成AIを思考拡張の補助装置として活用し、これまで到達しえなかった創造的洞察を得るための「AIリテラシー基礎ガイド」を解説します。
基礎的なAI活用の作法から発想テクニックまで、ビジネス現場で即戦力となる具体的手法を体系化しました。
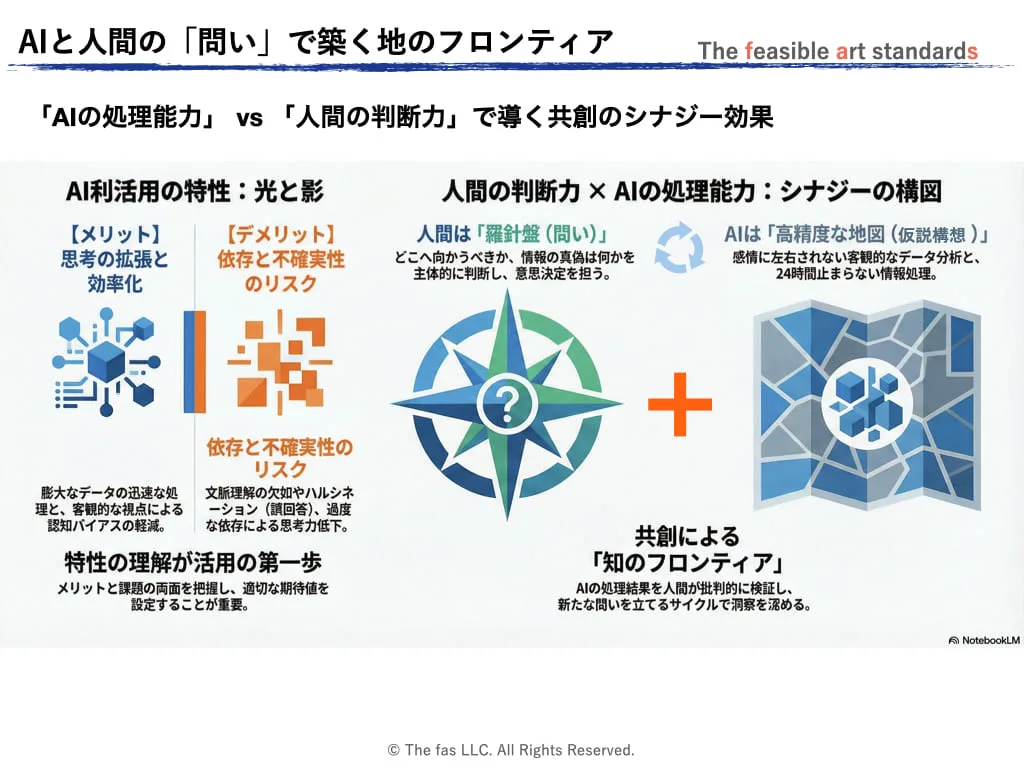
ビジネスにおける「問いの力」とAI活用は、現代の探検に例えられます。AIは高性能な地図や分析ツールを提供しますが、探検家である私たち自身が「どこへ向かうべきか」「何を探すべきか」「この情報は正確か」と自問し、批判的に検証することが不可欠です。
疑問を呈して行動を正す姿勢を持たなければ、膨大な情報に翻弄されたり、思考の方向性を誤るリスクが伴います。適切な問いは、AIを効果的に活用し、新たな発見や価値創造につなげる羅針盤となり、そこから、探検家自身の意思と主体性を示すものでもあります。
つまり、AI協働時代における「問い」の役割とは、人間固有の知的好奇心を原動力に、AIとの協働で「知のフロンティア」を切り拓くための最新型の羅針盤です。
これからAI活用を試みる方に向けた、「4大AIモデルの特徴と機能の比較表」や、の記事末尾の「AI用語集」と共に、あなたの思考を拡張させる知見をお届けします。
AI時代における課題と可能性
ビジネス変革を生む「問い」の力
AIの最大の特徴は、感情に左右されず、客観的かつ多角的に情報を処理できる点です。さらに、疲労などの生理的制約を受けないため、AIとの共創により、私たちは未踏の知的領域である「知のフロンティア」に挑むことができます。まず、人間の思考に内在する制約と、それを克服する手立てについて整理します。
人間の思考の限界とその影響
ビジネスでは迅速な判断が求められる一方、人間の思考には認知バイアスや疲労といった本質的制約があります。この限界を自覚することが、AIとの効果的な協働の第一歩となります。思考を妨げる主な2つの要因について、順を追って見ていきます。
障壁となる主な2つの要因
- 心理的要因
-
私たちの思考は、認知バイアスや固定観念に強く影響されます。たとえば、業界の常識に縛られて革新的なアイデアを見逃したり、新しい発想を組織が受け入れられなかったりすることがあります。こうした心理的要因は客観性を損ない、意思決定をゆがめる原因となります。
- 生理的制約
-
長時間の会議による疲労、睡眠不足、ストレスなどの身体的要因も、思考に大きな影響を与えます。疲労が蓄積すると集中力が低下し、複雑な問題に対する思考が鈍ります。その結果、本来なら導き出せるはずの解決策を見逃すことがあります。
次のセクションでは、こうした制約を乗り越えるために鍵となる「問い」の力と、それを活用する具体的な実践方法について掘り下げていきます。
ビジネス現場で直面する具体的な課題例
ビジネスの現場では、以下のような具体的な課題が日常的に生じています。
- 新規事業のアイデア発掘において、従来の成功体験にとらわれて斬新な発想が生まれない
- 組織の固定観念により、革新的なアイデアが排除されてしまうことがある
- 長時間の会議により、参加者の集中力の低下が建設的な議論の停滞を招く
これらの課題は、いずれも人間の認知的・心理的制約に起因しており、発想や意思決定の柔軟性を妨げる要因です。
ビジネス思考を変革する「問い」の力
変化の激しい現代のビジネス環境では、迅速な判断と柔軟な対応が求められます。しかし、認知の制約が思考の視野を狭め、意思決定の質を下げる要因にもなっています。
こうした状況を打破するためには、「問い」の精度を高め、思考に客観性を取り戻すための新しいアプローチが必要です。
適切な問いを立てることにより、組織の思考プロセスを活性化し、イノベーションの創出を促進する要因と考えられます。
- 認知の偏りが意思決定の妨げとなる
- ビジネス環境では瞬時の判断が求められる
- 高精度な問いが思考の柔軟性・客観性を向上させる
- 問いの活用が組織的なイノベーションの引き金となる
次項では、「問い」の精度を向上させる具体例を基に問いの立て方を考察していきます。
生成AIと共創するための優れた「問い」の条件とは?
優れた問いは好奇心から生まれ、現状を突破するアイデアの起点となります。AIとの対話では、この問いの精度が成果を左右する決定要因です。
ここでは3つの具体例を通じて、「問いの精度」がなぜ重要かを確認します。
- 例1: 新規事業アイデアを創出する
-
- Bad:「このアイデアは成功するだろうか?」
- Good:「どんな課題を、誰のために、どのような方法で解決するビジネスか?」
Point:問いが課題を構造化し、顧客像と市場ニーズを明確にする。
- 例2:顧客満足度を改善する
-
- Bad:「どうすれば顧客満足度が向上するのか?」
- Good:「顧客は、どのようなことに価値を見出しているのか?」
Point:ユーザー視点の問いが、潜在的な不満やニーズを可視化する。
- 例3:業務プロセスの課題を見抜く
-
- Bad:「業務改善について、何か良いアイデアはないか?」
- Good:「業務プロセスのどの段階で、ボトルネックとなる課題が生じているか?」
Point:因果関係が明確になり、根本的な要因に基づく対策を導く。
質の低い「問い」に共通するのは、その漠然さです。問いと仮説を連携させて論点を深める力が、思考の質を大きく左右します。
- 良質な問いは、問題の構造化と因果関係の解明を促す
- 問いは「目的・対象・手段」の明示で、評価基準を定める
- 質問の精度は、行動指針の実効性に直結する
- 漠然とした問いは、発想の深まりを妨げる要因となる
課題解決を実行するために論点を見定める「問い」の手順を、以下のコラムに再掲載します。
※タイトル(or▲)をクリックすると記事が現れます。
「問い」で論点を深める3ステップの思考プロセス
表面的な理解に留まらないために、多角的に偏りなく深く考察し問題の本質を探求します。
例:「扱うべき問題は、何であるか?」
事象を構成する要素や因果関係を明らかにし、目的に沿った論点を練り上げます。
例:「どんな要素や関係で、事象は成り立つのか?」
新たな価値を発見し、従来の枠組みにとらわれない発想を促進します。
例:「目的を満たすには、どのような手段や選択肢があるか?それは、模倣されやすいか?」
次章では、こうした問いの精度を活かしながら、AIを協働パートナーとした基本的な活用ポイントの理解を深めていきます。
AI利活用の勘所と技術的理解
ビジネス判断を支える新たな基礎スキル
生成AIについての理解を深めることで、ビジネスにおける活用イメージが明確になります。たとえば、人間関係においても、相手の特性を理解すれば円滑なコミュニケーションが可能になるように、AIの長所と短所を把握することが活用の第一歩となります。
AIへの期待と課題
- 期待:メリット
-
- 視野の拡張(バイアスの軽減):既成概念にとらわれず、複眼的なデータ分析が可能
- 迅速な処理(時間短縮):膨大なデータを短時間で収集・分析できる
- 正確な作業(業務の効率化):人手によるミスを防ぎ、精度の高い作業を実現
- 反復作業への耐性(生産性の向上):同一作業を繰り返し遂行できる持続性
- リソース不足の補完(自動化):人員不足の業務を補完し、全体の生産性向上に寄与
- 課題:(現時点の)デメリット
-
- 文脈理解の不足(柔軟性の欠如):背景や前提条件を完全に理解できない場合がある
- 独創性の限界(既存パターン依存):学習済みデータに依拠し、斬新な発想には限界
- 依存リスク(思考力の低下):過度なAI依存が、人間自身の判断・思考力の低下を招く恐れがある
- 誤回答の危惧(返答の不確実性):誤情報に基づく出力がなされるリスク
- 情報の漏洩(機密性への不安):プライバシーや機密情報の扱いに注意が必要
生成AIの期待値をどこに定めるか?
AIは単なる業務代替ツールを超え、思考パートナーとして機能します。AIの情報処理能力と人間の判断力を組み合わせることで、単独では到達できない発想も導き出せます。
インターネットやスマートフォンのように、AIも私たちの生活に深く入り込みつつあります。現段階のAIには限界があるものの、技術の進歩と社会構造の変化によって、今後はその課題も解消される可能性があります。
ビジネス現場において、生成AIは情報収集や解析といった判断材料の提示にとどまらず、人間の直感やひらめきを補完し、洞察力を深めるパートナーとなり得ます。
- AIリテラシーとは、AIの特性や限界を理解したうえで適切に活用する能力
- メリットと課題の両面を把握したうえで、適切な判断力を維持することが重要
- AIとの協働により、人間の創造力や洞察を補完可能
- 最終的な意思決定は人間が担うという原則を維持
【無料】基礎AIリテラシーを学べるオンライン講座
●AI For Everyone すべての人のためのAIリテラシー講座(Coursera 無料コース)
●Google AI Essentials日本語(Coursera 無料コース)
次のセクションでは、AI活用に欠かせない基本用語を通じて、生成AIの構造や仕組みへの理解を深めていきます。
生成AIを「基本キーワード」から深く理解する
ビジネス活用のための基本キーワード解説
生成AIの基礎構造を理解することで、より精密な指示と期待する成果を引き出せます。優秀な部下に仕事を依頼するように、AIの特性を把握することが活用精度を左右します。
生成AIにおいても同様に、基本構造への理解が、活用の質と精度を大きく左右します。ここでは、生成AIを理解するうえで重要となる基礎用語を、料理に例えてわかりやすく解説します。
※本稿文末に、生成AIの基本用語集を掲載しています。本文中の専門用語の確認などをご参照ください。
生成AIの基礎用語:『モデル』、『モデルアーキテクチャ』、『アルゴリズム』
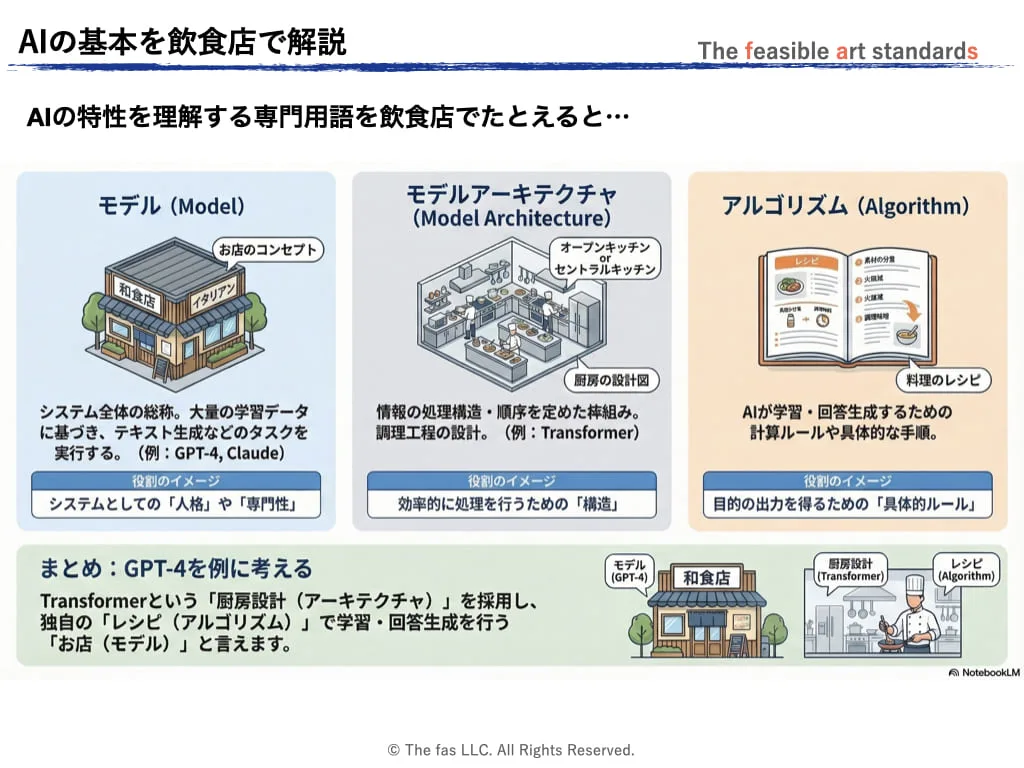
| 用語 | 概念 | 飲食店の例 | 具体例 |
|---|---|---|---|
| モデル | 大量なデータ学習のパターンを基に、テキスト生成や質問応答などのタスクを実行する仕組みの総称。広義ではシステム全体を、狭義では「GPT-4」「Claude」のような個別モデルの名称を指す。 | 飲食店の提供コンセプト(例:和食、イタリアンなど) | テキスト生成モデル GPT |
| モデルアーキテクチャ | 情報をどのような構造・順序で処理するかを定めた設計図。「Transformer」はその代表的なアーキテクチャであり、GPTやClaudeなど多くのLLMの基盤となっている。 | 厨房のレイアウトや調理工程の設計(例:セントラルキッチン方式、オープンキッチン) | Transformer |
| アルゴリズム | 目的の出力を得るために定められた、具体的な計算・処理の手順とルールの集合。AIの学習(パターンの習得)や推論(回答の生成)のそれぞれの場面で異なるアルゴリズムが使われる。 | 各料理の「レシピ」。食材の分量・火加減・調理時間など、手順を細かく定めた指示書 | 強化学習 ニューラルネット |
- この3つの関係を料理で整理すると次のようになります。
-
- 【モデル】=飲食店のコンセプト(和食/イタリアン)
- 【モデルアーキテクチャ】=厨房の構造・調理工程設計
- 【アルゴリズム】=個々の料理のレシピ
たとえば「GPT-4」は、Transformerアーキテクチャという厨房設計を採用し、独自のレシピ(アルゴリズム)によって学習・回答生成を行うモデルです。
日常会話では「モデル」がシステム全体を指す場合もありますが、厳密な定義を意識するより「全体像の把握」を優先することで、ビジネス現場での活用へ集中することが重要です。
※タイトル(or▲)をクリックすると記事が現れます。
大規模言語モデル(LLM)の仕組みと特徴:なぜAIの回答は毎回異なるのか?
大規模言語モデル(LLM:Large Language Model)は、膨大なテキストデータを基に、単語や語句の並びを予測しながら文章を生成するモデルです。GPTシリーズ(OpenAI社)、Claude(Anthropic社)などが代表例です。
LLMの出力には、次に続く単語を予測する確率的な生成手法が用いられています。このため、同じ質問に対しても毎回異なる回答が生成される可能性があります。これを制御する要素の一つが、ハイパーパラメータと呼ばれる設定値です。
この設定値は、出力の多様性や創造性を保つ一方で、特定のパターンに過度に依存しないよう調整されています。また、こうした確率的な出力は、「サンプリング」と呼ばれる方法で実現されており、プロンプトの書き方や実行環境によっても結果が変化します。
このように、AIが毎回異なる回答を生成する背景には、出力の多様性を確保する確率的サンプリング手法と、学習データに含まれる偏りやノイズという2つの要因があります。
AIとの対話では、この出力の「揺らぎ」を理解した上で活用することが重要です。
- LLMの回答が毎回異なる主な理由は2点:
-
- 確率的サンプリング:次の単語を確率的に選ぶため、同じ入力でも出力が変わる(意図的な設計)
- 学習データのノイズ・偏り:データに含まれる揺らぎが出力に影響する(制御困難な要素)
-
AIとの対話では、この「出力の揺らぎ」を前提として、複数回試行・クロスチェックを行うことが精度向上の鍵となる。
生成AIに的確な応答を引き出す鍵:「プロンプト」の基本と設計ポイント
生成AIを適確に動かす指示文:「プロンプト」とは
プロンプトとは、生成AIに対して与える指示文のことです。初期は記号やコマンドを用いた記述が一般的でしたが、現在では自然言語で十分にAIが理解・応答できるようになっています。
プロンプトの語源
プロンプト(prompt)は英語で「促す」「指示する」「思い出させる」といった意味を持ち、まさにAIの思考を引き出すためのトリガーとなる言葉です。
| Prompt | |
|---|---|
| 名詞 | 指示、(行動を)促す合図、ヒント |
| 動詞 | (行動を)誘発する、促す、想起させる |
| 形容詞 | 迅速な、即座の |
生成AIと生産的な対話ラリーの留意点
従来のAIは、文脈や背景知識の理解が浅く、人間の意図を正確に汲み取ることが困難でした。しかし近年では、コンテキスト理解やゼロショット学習といった技術革新により、AIの対話精度が大きく向上しています。
それでも、曖昧な問いではAIが誤解しやすく、意図に沿わない出力をする可能性があります。具体的な情報と前提条件を提示することで、対話の精度を高めることが可能です。
生成AIの不具合:ハルシネーション現象とは?
生成AIは、存在しない情報を事実のように生成してしまうことがあります。これを「ハルシネーション」と呼びます。その主な原因には、学習データの偏り、量的制約、推論時の誤った結びつきなどが挙げられます。
これは、人間が記憶違いをして誤った情報を信じる現象と似ています。生成AIに対しては、事前に目的や条件を明確に伝えることで、こうした誤った情報処理リスクを軽減できます。
生成AIを情報収集などに利用する際には、ファクトチェックによる裏取り作業が不可欠です。筆者は実際の執筆や検証の場面において、複数の生成AIモデルを併用し、あるAIの出力を別のモデルで“クロスチェック(ダブルチェック)”する手法を採用しています。

主に、ChatGPT、Gemini、Claude、Perplexityの4モデルを利用し、それぞれの特性に応じて組み合わせを変えることで、出力の精度と信頼性を担保します。
以下のコラムに、これらのモデルの特徴を簡潔に比較した表を掲載します。
※タイトル(or▲)をクリックすると記事が現れます。
生成AIサービスの4モデル:機能と特徴の比較表(2025年8月27日現在)
- ChatGPT
-
- 開発元:OpenAI
- モデルタイプ:GPT-5(無償版:ChatGPTアプリ標準)、GPT-5 mini/nano(無償版:軽量版)、GPT-5(有償版:Plus/API/Thinkingモード向け)、GPT-4o(有償版:復活提供)
- 技術仕様:
- 自己回帰型LLM
- マルチモーダル対応(テキスト・画像・音声)
- Thinkingモード:最大256,000トークンの入力処理(出力トークンは含まれない)
- API:最大272,000トークン入力+最大128,000トークン出力、合計最大400,000トークン処理可能
- 機能呼び出しや安全制御の実装あり
- 特徴:
- 無償版でもマルチモーダル使用可
- 有償版で高速応答や思考深度が向上し、より大規模な文脈を処理
- コーディング支援や記憶機能、GPTsによるカスタム化が充実
- 得意分野:
- 文章作成・要約・翻訳
- プログラミング支援
- マルチモーダル問答
- 業務ドキュメント生成
- 総評:ChatGPTを単一の製品ではなく、多様なAIサービスの中央ハブへと「プラットフォーム化」することを目指す最も包括的なAIツールキット。
- Gemini
-
- 開発元:Google DeepMind
- モデルタイプ:Gemini 2.5 Flash(無償版:低遅延/コスト効率)、Gemini 2.5 Pro(有償版:高性能)、Gemini 2.5 Flash Image(有償版:画像生成/編集特化)
- 技術仕様:
- マルチモーダル対応(テキスト、画像、音声、動画入力)
- “Thinking/Deep Think”系の推論モードを搭載
- Flashは速度重視、Proは複雑な推論やコーディング適応性が進化
- クラウド(Vertex AI)では約1Mトークン級の長文処理が可能
- 特徴:
- 無償版: Google検索や画像生成の基本機能を無料で利用可能。
- 有償版: Google Workspaceとの連携、より高度なマルチモーダルの機能やプロンプト制御が可能。
- Flash Image: 画像の編集や生成に特化した機能を持つ
- 得意分野:
- マルチモーダル生成・画像編集
- リアルタイム情報とGoogleエコシステムとの連携
- 複雑な解析・コーディング支援
- 資料作成
- 総評:単なるチャットボットではなく、Googleの膨大なデータとサービスを活用して、比類のない利便性と価値を提供する包括的な生産性ツール。
- Claude
-
- 開発元:Anthropic
- モデルタイプ:Claude Sonnet 4(無償版:高効率・バランス型)、Claude Opus 4.1(有償版:最上位・高性能)
- 技術仕様:
- Constitutional AI設計による安全制御
- 即座の応答と拡張思考モードのハイブリッド型
- Sonnet 4:64K出力トークン、API経由で100万トークンコンテキスト対応
- Opus 4.1:32K出力トークン、改良されたコーディング能力
- 特徴:
- 拡張思考モード(最大64,000トークンの内部処理)
- インターリーブ思考(思考中のツール実行)
- 100万トークンコンテキストウィンドウ
- コード実行・ファイルAPI・プロンプトキャッシュ機能
- Constitutional AIによる安全性制御
- 得意分野:
- 長文処理
- コーディング
- 複雑な推論タスク
- 安全重視のユースケース
- 創作文・論文・法務ドキュメント
- 総評:汎用的なツールを目指すのではなく、精度、安全性、そして長文の理解が不可欠な分野で卓越することに焦点を当てている。
- Perplexity
-
- 開発元:Perplexity AI
- モデルタイプ:Standard(GPT-4o*、Claude 3.5 Sonnet、Deepseekなど多数)/Pro(Llama 3.1 405B 等高性能モデル・有料)。*2025年8月26日時点では、GPT-5はOpenAIの最先端モデルとして発表済みだが、Perplexity AI内での完全統合は現在進行中。
- 技術仕様:
- LLM+リアルタイムウェブ検索統合
- 出典明示
- マルチモーダル(ファイルアップロード・AI画像生成・動画検索)対応
- 特徴:
- 出典付き応答で高信頼の情報提供
- 最新データや学術・文化情報に強い
- さまざまなAIモデルを用途に応じて選択可能
- 2025年3月実装のディープリサーチ機能で多角的調査レポート生成可能
- AIエージェント「Perplexity Assistant」による複雑タスクの自律的実行(予約・配車等)
- 得意分野:
- 学術
- 文化情報
- リアルタイム調査
- ファクトチェック
- 総評:「リサーチッスペシャリスト」としてリアルタイムのウェブ検索機能を統合しており、ニュースや学術研究、最新の出来事に関する調査に特に強みを持つ。
これらの特性を理解し、状況に応じて使い分けることは、生成AIの実務的活用力(AIリテラシー)を高める上で重要です。
次章では、生成AIと共に創造的思考を展開するための「発想プロセス」に注目し、実践的なテクニックを解説していきます。
生成AIとの創造的対話:実践テクニック
生成AIと対話を深める鍵:
生成AIとの対話は、自分の思考を整理し深める手段として非常に有効なツールとなります。とりわけ一人でアイデアを練る場合、AIを自身の思考を深める「壁打ちパートナー」とすることで、ソロ・ブレインストーミングの実施が可能となります。
本稿では、アイデアを創出するプロセスを「発想 → 発散 → 収束」の3ステップに分け、それぞれにおけるAIの役割と活用法を整理します。
AIと共創するためのアイデア発想の3ステップ
- 1.発想の準備段階:テーマとなる方向性や目標策定、情報収集
-
- まずは、アイデアを導くためのテーマや目標を明確にします。
- この段階では、AIを使って幅広い情報を収集し、要点を整理することで、企画や構想の土台を形成できます。
- 2. アイデアの発散:視野を広げる
-
- 生成AIは大量の知識を基に、多角的な観点から提案が可能です。
- キーワードの周辺情報を収集・提示させることで、思考の幅を広げ、創造的な連想を引き出すことができます。
- 3. アイデアの収束:評価と整理
-
- 発散された案を評価し、優先順位を付けて整理する段階です。
- 生成AIは市場動向や過去の事例からパターンを抽出し、実現性やリスクの検討を支援します。意思決定に向けた材料を多角的に提示できる点が強みです。
- アイデア創出は「発想→発散→収束」の3ステップで整理
- 準備段階では生成AIによる情報収集と要点整理が有効
- 発散では多角的視点を引き出し、発想の幅を広げられる
- 収束では事例分析などを通じて実行可能性を見極められる
- 対話型パートナーとしてAIを位置づけることで、思考の効率と質を高める
次章では、生成AIと創造的なブレストを成功させるために必要な「プロンプト設計」の実践的な方法について詳しく解説していきます。
生成AIとブレインストーミング:成功を導く実践ガイド
AIとの対話において、期待した回答が得られない経験は少なくありません。こうした手戻りを防ぐには、効果的な対話設計が欠かせません。
とくに初めてAIとやり取りをする場面では、基本的な「作法」を理解し、目的や文脈を明確に伝えることが、建設的なブレストに繋がります。
生成AIと創造的対話を実現する5つのプロンプト設計法
- 1. 問いの目的を明示する
-
- 曖昧な問いかけでは、AIの応答も抽象的・不正確になりがちです。
- 例:「売上を伸ばす方法は?」→「新商品のターゲット層別に、売上予測を立てるには?」(目的や条件を具体的に設定する)
- 2. 背景や意図する補足情報を提示
-
- 文脈や前提条件が提示されないと、AIは適切な判断が困難になります。
- 例:「競合他社と差別化はどう取れるか?」→「以下が競合A社と自社の概要。比較して差別化案を検討する」(補足情報を含める)
- 3. 複数の問いを同時に含めない
-
- 一文に複数の質問を含めると、要点が曖昧になります。
- 例:「新規顧客の獲得と既存顧客維持の戦略は?」→「まず新規顧客の獲得方法を検討する。その後、既存顧客の維持施策を考える」(接続詞で文章を分割する)
- 4. 段階的に思考を深める
-
- 問いを分解し、順を追って検討させることで論点が明確になります。
- 例:「マーケティング戦略を最適化するには?」→「課題を3つ挙げて、それぞれに対する対策を検討する」→(問題点を分解して問う)
- 5. 情報源の確認を求める
-
- 生成AIの出力には誤情報が含まれる可能性があるため、出典提示を求めることが有効です。
- 例:「アフリカの環境問題は?」→「主な要因と参照元(URLなど)を明示する」(情報元の提示)

このように、プロンプト設計には5つの基本視点があります。
次章では、こうした設計法を活かしながら、生成AIとともに文章構成を練り上げる実践手順を紹介します。
生成AIと共に文章の構成を練る
AIとの共創において、構成力を高めるためには、プロンプト設計から情報分類・構成案の検討までを段階的に実行することが重要です。以下に、その具体的なステップとプロンプト例を提示します。
プロンプト設計から文章構築までの実践ステップ例
目的:生成AIがテーマを深掘りするための前提情報を与える
プロンプト例(要素):
- あなたは大手出版社の編集者です
- 対象読者:生成AIを活用してアイデア出しをしたいビジネスパーソン
- 仮テーマ:生成AIと協働し、ユニークなアイデアを発想するブレスト技術
- タスク:テーマを推敲し、キーワード案を3件ずつ提示し、その理由を200〜300字でまとめる
AIの役割や読者像、前提条件を明確に示すことで、意図したアウトプットを得やすくなる
目的:読者のニーズに合ったコンテンツ要素を多面的に検討
プロンプト例(要素):
- 記事テーマに基づき、3案の構成案を提案
- 各案には具体例と理由を添える
- 出力形式は表組みで視認性を確保
比較検討しやすい形式で提示することで、AIの提案を俯瞰しながら検証・深化できる
目的:得られた要素を分類し、構成案へと昇華する
プロンプト例(要素):
- 出力形式は表形式
- グループ分類に名称を付ける
- 各要素に短い説明を加え、最終的な構成案を箇条書きで提案
情報の整理・統合を通じて、構成の完成度が高まり、論点の明瞭化が図れる
生成AIを構成パートナーとして活用することで、情報整理から解放された人間は、より創造的な企画立案と想定読者への価値提供に専念できます。
次章では、AIに対して指定文字数で文章を出力させるための具体的なプロンプト設計を紹介します。
生成AIとの構成作業では、まずプロンプトでAIの役割を明示し、対象読者や仮テーマを提示することが重要。構成要素の分類・検討・整備といった手順を明確にすることで、質の高いアウトプットと創造的対話が実現できる。
※タイトル(or ▲)をクリックすると記事が現れます。
【コラム】生成AIに指定文字数で文章を書かせるためのプロンプト設計例
生成AIに文章作成を依頼しても、指定した文字数どおりに出力されないケースは少なくありません。これは、日本語が持つ複雑な文字種(漢字・ひらがな・カタカナ・記号など)や、文字幅(全角・半角)、*トークン処理方式に起因しています。*トークンとは、AIが文章を理解するための前処理として文章を単語や文字などの意味を持つ単位に分割した単位のことを指します。
AIが自然言語を処理する際の単位である「トークン」は、日本語では文字や文節単位で区切られるため、文字数の制御が欧文よりも難しくなっています。
こうした問題に対処するためには、プロンプト内で文字カウントの基準を明示的に定義する必要があります。
【前提条件】
- 文字数は明示されたカウント方式に基づいて厳密に計測する
- 指定された文字数(例:300文字)と実際の出力が一致した場合にタスク完了とみなす
【制約条件】
- 句読点・記号はすべて全角文字で表記し、1文字と数える
- 英数字は半角文字で表記し、1文字と数える
- 空白や改行はカウント対象外とする
- 文字コードはUTF-8とする(必要に応じて、文字コードを指定する)
【タスク】
- 指定テーマに対する要約文を、全角300文字以上・350文字以内で作成する
- 上限・下限の両方を設け、文字数調整の精度を高める
※上限数だけでなく、下限の文字制限を設けることで適切な分量の文章を出力させる
- イエローのハイライト:文字のカウント方式の定義
- ブルーのハイライト:カウント精度を高める前提条件
最後にAI活用において、人間に求められるスキルや姿勢について考察を深めます。
おわりに
AI時代に必要なコアスキル:人間力とは
2025年1月に発表された世界経済フォーラム(WEF)の「仕事の未来レポート2025」では、企業が人材に求める主要スキルの変化が明らかになりました。
ランキング上位には、以下のような思考系スキルが並んでいます:
- 第1位:分析思考(Analytical thinking)
- 第4位:クリエイティブ思考(Creative thinking)
*分析思考とは、事象の因果関係などを事実を基に客観的に読み取り論理的に原理を見いだす思考プロセス。
参照元:Future of Jobs report 2025 WEF

さらに、2030年に向けて需要が高まるスキルとしても、クリエイティブ思考や分析思考は引き続き注目されています。

これらの変化は、AI技術の進展とともに、人間にしかできない領域の価値が再評価されていることを示しています。とくに、好奇心や学び続ける力、柔軟な思考といったソフトスキルの重要性が高まっています。
また、不確実な時代においては、「*審美眼」や「内省的思考」によって深い洞察を得る力が、自己効力感(self-efficacy)を支える要素ともなります。
*審美眼とは、美の本質を見抜く力のこと。表面的な美しさだけでなく、内面的な価値や意味を理解する能力を指す。
「問う」ことが人間の根源を示す
変化に直面する瞬間、私たちの心に宿る知的探究心は、物事の本質を理解したいという純粋な欲求として覚醒します。「問い」を立てる行為は人間固有の能力であり、不確実な未来を切り拓く最も強力な原動力となります。
真の問いは、意図と目的、そして深い意味を纏いながら形成され、感情の奥底から湧き上がる思考の源泉です。生成AIとの協働においても、この人間の内発的な探求心こそが、思考と行動の羅針盤として機能するのです。
激変する時代の只中で、人間が武器とすべきは「問う力」そのものです。AIという知的パートナーを迎えた今、従来の思考の殻を打ち破り、未踏の領域へと果敢に挑戦する千載一遇の好機が眼前に広がっています。
真に重要なのは、AIへの従属ではなく、AIとの共進化です。知的好奇心を推進力とし、研ぎ澄まされた問いを指針に、人間とAIが織りなす創造的協働によって「知のフロンティア」を切り拓く力こそ、AI時代における究極の競争力です。
- 「問い」は、人間の内発的思考を促す根源的行為である
- 問いを精緻化することで、既存の前提や固定観念から脱却し、思考の自由度を拡張する
- 生成AIは、多様な視点の提供と人間の思考補完という役割を担う
- その結果、人間が見落としがちな観点を補完し、検討の幅が広がる
- 生成AIと効果的に協働するには、AIリテラシーの習得と創造的な姿勢の両立が不可欠
- AI活用の拡大に伴い、知的好奇心と探究心を持続する姿勢が、人間にとって一層重要となる
生成AIを理解するための「基本のAI用語集」
※各タイトルをクリックすると、詳細な解説が表示されます。
AIの基礎知識
1. 機械学習 (Machine Learning; ML)
機械学習とは、大量のデータから規則性やパターンを自動的に学び、新しいコンテンツを生成する能力を獲得するプロセスを指します。
画像、テキスト、音声などのトレーニングデータを基に、AIが創造的なタスクを実行できるようになる基盤技術です。深層学習の発展により、より自然で高品質な生成が可能になりました。
参照元:機械学習とは?
2. 深層学習 (Deep Learning; DL)
深層学習は、多層ニューラルネットワークを用いてデータから特徴を自動的に学習するAI技術です。各層の情報伝達と処理を行う「ニューロン」が、重要なパターンを抽出します。
ニューロンは情報を、統合・活性化して次の層に伝達し、これを繰り返すことで複雑な問題を解決します。この仕組みが、生成AIによる画像や文章などの新しいコンテンツ生成を可能にしています。
3. ニューラルネットワーク (Neural Network; NN)
ニューラルネットワークとは、人間の脳の神経回路を模倣した計算モデルであり、AIの基幹技術のひとつです。入力層、隠れ層、出力層で構成され、各層の「ニューロン」が情報を処理・伝達します。
隠れ層がデータの特徴を抽出し、複雑なパターンを学習することで、画像認識や自然言語処理などを可能にします。生成AIでは、この技術を活用し、新しい画像や文章を創造的に生成します。
4. 事前学習 (Pre-training)
事前学習は、AIモデルが大量のデータを学習し、汎用的な知識を獲得する初期工程です。例えば、テキストではBERT、画像ではResNet、音声ではWav2Vecなどが活用されます。事前学習済みモデルは、続く下流工程のファインチューニングにより、限られたデータでも性能の向上が可能です。これにより、専門的なタスクへの効率的な適応が可能になります。
5. 教師あり学習 (Supervised Learning)
教師あり学習とは、正解ラベル付きのデータを用いてAIを学習する手法です。例えば、生成AIの画像生成モデルでは、「ネズミ」とラベル付けされた多数のネズミの画像を学習させます。これにより、AIは「ネズミ」の特徴を理解し、新たなネズミの画像を生成したり、初見の画像がネズミかどうかを判断したりできるようになります。
6. 教師なし学習 (Unsupervised Learning)
生成AIにおける教師なし学習とは、正解ラベルのないデータからパターンや規則性を見出す学習手法です。類似した特徴を持つものをグループ化することで、新たな構造や関係性を発見します。この技術は顧客セグメンテーションや異常検知などのビジネス応用で活用されます。
参照元:教師なし学習-SoftBank
生成AIの基幹技術・概念
1. 大規模言語モデル (Large Language Model; LLM)
膨大なテキストデータを学習して自然な言語生成や理解を行う深層学習モデルです。Transformerを基盤とし、文脈を考慮した文章作成や翻訳、質問応答などを高精度で実現します。生成AIの一種として、ChatGPTやGoogleのBERTなどが代表例であり、人間のような流暢なテキスト生成が可能です。
参照元:大規模言語モデル-NRI
2. 自然言語処理 (Natural Language Processing; NLP)
自然言語処理(NLP)とは、人間の言語をコンピューター側が理解・解析・生成する技術で、対話型の生成AIの基盤となる分野です。生成AIでは、NLPを活用してテキストデータを学習し、文章の意味を理解しながら新しい文章や会話を生成します。これにより、ChatGPTのような対話型AIや文章要約、翻訳など、多様なタスクを実現しています。
3. トランスフォーマー (Transformer)
トランスフォーマーは、生成AIの基盤となる深層学習のモデルアーキテクチャです。自己注意機構により、文脈を捉えながら並列処理を行うことで、高速かつ高精度な予測・生成を実現します。 GoogleのBERTやPaLM、ChatGPTなどの大規模言語モデルの中核技術であり、自然言語処理、画像生成、翻訳など幅広い分野で革新的な成果を上げています。
4. 強化学習 (Reinforcement Learning)
強化学習は、AIが経験を通じて最適な行動を学ぶ手法です。AIは、環境でさまざまな行動を試し、その結果得られる報酬を基に行動を改善します。報酬は行動を評価する指標で、例えば自動運転では目的地に安全に到達することや、ゲームAIでは勝利が高い評価になります。
この方法は、自律的な意思決定が求められる分野で活用されています。
5. ランダム性(Reasoning and Acting)
ランダム性とは、生成AIが同じ入力に対しても多様な出力を生成する機能です。これは「温度」パラメータという値で制御され、低温値では安定性が高く、高温値では表現の多様性が増します。金融や医療では低温で安定性を重視し、画像生成などアートや創作では高温設定が適しています。一部の生成AIサービスでは温度調整が可能ですが、サービスによって機能や制限が異なります。AIのランダム性は新たな発想を促す一方、予期せぬ結果も生み出します。
生成AIを使いこなす
1. トークン (Token)
トークンとは、生成AIが扱う最小のデータ単位です。例えば、「今日は私の誕生です。」という文章をAIが理解するために、「今日」「は」「私」「の」「誕生日」「です」「。」という7つの単位に分割されます。この処理をトークン化と言います。
AIは、このトークン単位で文章を理解したり、生成します。トークンは、AIにとっての言葉のパズルのピースのようなもので、AIはこのピースを組み合わせて文章を理解し、生成します。AIの学習データ量や計算コストにも影響するため、効率的なトークン化が重要です。
2. プロンプト (Prompt)
生成AIにおける「プロンプト」とは、AIに対して具体的な指示や質問を与えるためのテキスト入力のことです。例えば、「鳥がさえずる森の景色をイラストに描いてください」と入力すると、AIはその内容に基づいて画像を生成します。プロンプトの内容やタスクの詳細さによって、生成結果が大きく変わるため、明確かつ具体的な指示が肝要です。
3. プロンプトエンジニアリング (Prompt Engineering)
生成AIから望ましい出力を得るためのプロンプト設計・最適化技術です。例えば、「以下の文章を、要約してください」より、「以下の文章を、100文字以内で簡潔に具体例を交えて要約してください。」とすることで、より的確な回答を引き出せます。効果的なプロンプト作成により、AIの性能を最大限に引き出し、様々なタスクを効率的に実行できます。
4. AIエージェント (AI Agents)
AIエージェントとは、特定のタスクや目標を自律的に遂行するAIシステムです。環境を認識し、判断を下し、行動を実行する能力を持ちます。2024年に注目され、2025年も引き続き話題です。ビジネスでは、自動化されたカスタマーサービスや個人向けAIアシスタント、自律型ロボットなどに活用されています。例えば、ZendeskのAIエージェントは顧客対応の80%を自動化し、効率化とコスト削減を実現しています。
参照元:AI エージェントとは?-AWS
5. AIオーケストレーション (AI Orchestration)
えば、ECサイトでは商品説明AI、顧客行動分析AI、商品推奨AIを連携させ、個別化された購買体験を提供します。医療分野では、画像診断AI、問診AI、治療計画AIを連携し、診断から治療までを支援します。課題は、AIモデル間の連携におけるデータ整合性、処理速度、適切なモデル選定、運用管理です。対策は、各AIの役割を明確化しインターフェースを共通化し、導入時に業務担当が理解しやすツールに仕上げることです。
6. エッジAI (Edge AI)
エッジAIとは、AIを端末(エッジデバイス)に直接搭載し、クラウドを介さずにその場でデータ処理を行う技術です。例えば、自動運転車はカメラやセンサーで収集したデータをリアルタイムで分析し、安全な運転を支援します。この仕組みにより、低遅延、通信コスト削減、プライバシー保護が可能となり、IoTや産業用ロボットなど幅広い分野で活用されています。
参照元:エッジ AI とは-RedHat
7. マルチモーダルAI (Multimodal AI)
マルチモーダルAIは、テキスト、画像、音声など多様なデータを同時に扱えるAIです。例えば、画像を見て説明文を作ったり、文章から画像を生成できます。ビジネスでは、商品説明の自動作成や、マルチメディアコンテンツの分析に活用されています。これにより、より自然で状況に応じたAIの活用が可能です。
参照元:マルチモーダルAIとは?-@IT
8. アンラーニング (Unlearning)
アンラーニングは、AIモデルから特定データの学習の影響を取り除く技術です。個人情報を含む学習データや著作権侵害の疑いがあるデータの影響を無効化し、プライバシー保護に役立てます。ただし、モデル内部に拡散した情報の完全な除去は困難です。実装では再学習やモデル編集などを活用し、データの残存リスクを最小限に抑えます。
9. ファイン・チューニング (Fine-tuning)
ファインチューニングとは、事前学習済みの大規模AIモデルを転移学習の手法を用いて特定の用途や目的に適応させる技術のことです。画像生成AIや言語モデルなどを、企業独自のデータで再調整することで、自社ニーズに合わせた専用AIを構築できます。
明確な正解がある特定タスクで性能向上を目指す際に有効です。ただし、成果の質は、トレーニングデータの品質と量に大きく依存します。
参照元:ファインチューニングとは:IBM
10. インストラクション・チューニング (Instruction Tuning)
ユーザーの指示を正確に理解し、意図に沿った適切な応答の振る舞いを調整する学習手法です。これはファイン・チューニングの一種ですが、特定の用途・目的向けではなく、多様な指示に対応できる主力の最適化が特徴です。また、人間の介在による強化学習(RLHF)と異なり、報酬モデルを使わず、人間が作成した大量の事前データセット(LLM)を調整します。メリット:汎用性の高さや透明性の確保、意図に沿った応答の向上が挙げられます。デメリット:データ作成にかかる時間やコスト、人間のバイアスにおける影響の可能性があります。
生成AIの発展技術
1. 転移学習 (Transfer Learning)
転移学習とは、学習済みモデルの知識を別のタスクに応用する手法です。例えば、画像認識AIが猫や犬の識別を学習した後、その知識を活かして車の種類を識別するタスクに応用できます。
ゼロから学習する場合に比べ、転移学習は少ないデータで効率的に学習を進められます。特に、医療画像のように大量のデータ収集が難しい分野では、転移学習が有効です。特に、AI開発の効率化に貢献する重要な技術です。
2. フェデレーテッドラーニング:連合学習 (Federated Learning)
フェデレーテッドラーニング(連合学習)とは、データを中央サーバーに集めず、各デバイスが個別にモデルを学習し、その結果のみを統合する分散型機械学習手法で、プライバシーを保ちながら機会学習モデルを向上させます。医療や金融など、機密性の高い医療機関や金融・行政期間で活用されています。
3. メタラーニング(Meta-learning)
メタラーニングとは、AIが学習の方法そのものを学習する技術です。過去の経験を活かして新しい課題に素早く対応できるため、少ないデータでも効果的な生成AIモデルを構築できます。ビジネスでは、新規分野への展開や個別化モデルの開発に役立ち、例えば限られたデータから効率的なパーソナライズされたマーケティング展開も可能です。
参照元:メタ学習とは?-IBM
4. HITL:人間参加型AI (Human-in-the-Loop)
HITLとは、人間がAIの学習や意思決定プロセスに介入し、フィードバックや模範行動を提供することで、AIの性能や信頼性を向上させる手法です。例えば、人間がAIの出力結果を評価・修正し、それを基にAIが再学習することで、より安全で精度の高い振る舞いを実行するAIシステムが構築されます。
5. RAG:検索拡張生成(Retrieval-Augmented Generation)
大規模言語モデル(LLM)は、学習済みの情報のみで応答を生成するという制約があります。RAG(検索拡張生成)は、質問内容に応じて独自の知識データベースから関連情報を検索し、LLMに連携することで、学習データにない独自の知識や専門情報の活用を可能にします。これにより、LLM単独では難しい高度な情報検索を実現できます。
参照元:生成AIのRAGとは?その仕組みや作り方、活用事例を解説

6. RLHF(Reinforcement Learning from Human Feedback))
RLHF(人間のフィードバックによる強化学習)は、AIの出力を人間の価値観に合わせる機械学習の手法です。ChatGPTを例に挙げると、人間の評価を基にAIが自動で学習します。一方、HITLは運用段階で人間が介入しますが、RLHFほど直接的なモデル改善はしません。また、ファインチューニングは、特定のタスクに特化した事前学習モデルの調整を指し、RLHFとは異なります。
7. GAN:敵対的生成ネットワーク(Generative Adversarial Network)
GAN(敵対的生成ネットワーク)は、生成器(ジェネレーター)と識別器(ディスクリミネーター)の2つのAIを競合させることで学習を行う技術です。生成器は、例えば実在する人物の顔写真に似た画像を生成します。一方、識別器は生成された画像が本物か偽物かを見分けようとします。この攻防を通じて、生成器はより本物に近い画像を生成できるようになり、識別器も識別能力を高めます。
参照元:GANとは何ですか?-AWS
8. 知識蒸留 (Knowledge Distillation)
知識蒸留とは、大規模モデルの知識を軽量なモデルへ伝達する技術です。高精度な教師モデルは計算コストが高く、軽量な生徒モデルは精度が低いという課題を解決します。
DeepSeekは知識蒸留を効率化する手法を研究しており、特に大規模言語モデル分野で注目されています。DeepSeekの手法を用いることで、生徒モデルは教師モデルの知識を効果的に学習し、高い性能を維持したまま軽量化・高速化できます。
知識蒸留は計算資源に制約のある環境でのAI活用を促進する重要技術であり、DeepSeek等の研究開発により進化し、さまざまな分野への応用が期待されています。
9. 説明可能なAI (Explainable AI; XAI)
説明可能なAI(XAI)は、AIの意思決定プロセスを従来のブラックボック化から人間が理解できる形で説明する技術です。医療では診断画像の部位をヒートマップで可視化したり、金融では融資審査の透明性を向上させます。XAIは信頼性向上や倫理的課題への対応に有効ですが、計算コスト増加やバイアス対応、プライバシー保護などの課題も抱えています。
参照元:説明可能なAIとは-IBM
リスクと課題
1. AI倫理 (AI Ethics)
AI倫理とは、人工知能(AI)の開発・利用が社会や個人に悪影響を及ぼさないようにするための原則や実践指針を指します。例えば、AIによる差別や偏見の排除、プライバシー保護、透明性の確保などが含まれます。生成AIの分野では、人種や性別による偏見を含んだコンテンツの生成を防ぐ仕組みや、倫理的な問題点がないかを人間がチェックするレビュー体制が重要視されます。
2. ハルシネーション (Hallucination)
ハルシネーションとは、AIが事実と異なる情報を回答する現象です。人間の幻覚に似た、もっともらしい誤った発言を指します。例えば、「2024年のノーベル賞受賞者は、ドナルド・トランプです」といった証拠のないを回答をすることがあります。これはAIが学習データの誤った関連性を紐付けたり、不完全な情報処理を行うために発生します。
対策として、高品質な学習データの使用、専門家によるレビューなど人間のフィードバックによる強化学習(RLHF)、出力結果の検証プロセス強化が必要です。
参照元:ハルシネーションとは-NRI
3. データバイアス (Data Bias)
AIのデータバイアスとは、学習データの偏りにより出力が不公平や不正確になる現象です。例えば、特定の性別や人種のデータ不足で、その属性の予測が誤ったり不平等になる可能性があります。対策として、データの多様性確保、リバランス手法による属性補完、継続的なモデル評価が重要です。さらに、バイアス検出ツールを活用し公平性を向上させます。データバイアスはAIの信頼性に大きく影響するため、慎重な対応が必要です。
4. 推論遅延 (Inference Latency)
推論遅延とは、AIモデルがプロンプト入力を受領してから出力を生成するまでの時間を指します。例えば、ChatGPTのような対話型AIで、ユーザーの質問に対する応答が表示されるまでの時間がこれに当たります。低遅延では、リアルタイム性が求められるアプリケーションでは重要性を増します。
推論遅延の対策には、モデルの軽量化、キャッシング、CPU最適化ツールの活用、AUTOデバイス選択モードの利用などがあります。これらにより、精度を維持しつつ推論速度を向上させることができます。
その他
1. 世界モデル (World Model)
世界モデルとは、大規模な学習データから現実世界の構造や因果関係を観測から学習し、推論を行う枠組(技術の一つ)です。これにより、物理法則を再現したり、複雑な状況での行動を予測したりすることが可能です。ただし、学習データの偏りによるバイアスの発生には注意が必要です。例えば、「特定の行動が必ず特定の結果を生む」と誤認される可能性があります。故に、重要な意思決定には人間の確認が不可欠であり、医療や法的判断などでは、特に慎重な検証が求められます。
2. ゼロショット学習 (Zero-Shot Learning)
事前に学習していないデータに対して、文脈や知識を活用し推論を行う技術です。画像認識では説明文を基に未知の物体を認識し、自然言語処理では未学習のタスクを簡易指示でも実行します。例えば、「馬に似て白黒の縞模様がある」という説明からシマウマを識別できます。課題は情報不足や曖昧な説明により誤った推論が生じる点です。対策として、大規模言語モデルの活用や適切なプロンプト設計が重要です。この技術はAIの汎用性が向上します。
参照元:ゼロショット学習とは-IBM
3. 推論モデル (Reasoning model )
推論モデル(Reasoning model)とは、生成AIの中でも「じっくり考えて答える力」を持ったタイプのAIです。従来の生成AIは、事前学習で与えられた情報から明示的な中間思考ステップを示さずに回答を直接生成します。推論モデルでは論理的な思考のプロセスを経て答えを導きます。
たとえば、複雑な質問に対して、問題を小さな要素に分けて順を追って考え、最終的に結論を導き出します。
推論モデルを使うことで、数学の問題やビジネス上の複雑な判断など、正確さや一貫性が求められる場面でも、より信頼できる答えを得ることが可能です。その反面、従来のモデルに対して、推論モデルは思考時間が必要なため応答速度(レイテンシー)が遅くなり、また、複雑な推論を行うため、より多くの計算リソースを消費します。
このような「思考プロセスの明示性」と「多段階の処理」で正確性の向上が推論モデルの特徴であり、用途に応じて適切なモデルを選択することが重要です。
参照元:https://www.ai-souken.com/article/what-is-reasoning-model
4. ReAct (Reasoning and Acting )
大規模言語モデル(LLM)が、推論(Reasoning)と行動(Acting)を 観測を交えて繰り返し行い、複雑なタスクを解決する枠組です。例えば、質問に対して関連情報を検索し(Acting)、その結果に基づいて回答を生成します(Reasoning)。この過程を繰り返すことで、外部環境との連携や段階的な問題解決が可能になります。事実に基づいた正確な回答や、複数ステップを要するタスクの実行に優れており、質問と応答や意思決定支援など幅広い分野で活用されています。課題は、情報源の信頼性や検索効率性です。性能の向上で、より複雑なタスクの自動化が期待されます。
参照元:ReAct: Synergizing Reasoning and Acting in Language Models-note:npaka
参考文献&WEBサイト
- 岡瑞起ほか 「『AI時代の質問力』 プロンプトリテラシー 」:翔泳社 2024年
- 安藤昭子 「問いの編集力 思考の『はじまり』を探究する」:ディスカヴァー・トゥエンティワン社 2024年
- 比治山大学 社会臨床心理学科吉田ゼミHP:公開オンライン授業「知覚・認知心理学:12.思考の過程」:2025年1月14日閲覧
- 第一生命経済研究所WEBサイト:「『ブレインストーミングAIの衝撃』」:2025年1月20日閲覧
- RICHOのAI:仕事のAI:「『大規模言語モデル(LLM)とは』」:2025年1月27日閲覧
- Forbes JAPAN:「AIを使いすぎると人は愚かになる 研究でわかった『認知的オフロード』」:2025年1月24日閲覧
- Forbes JAPAN:「企業が求めるスキル首位は「分析的思考力」、最新調査」:2025年2月3日閲覧
- Forbes JAPAN:「問いを立てる力が「人間中心のAIアプローチ」を実現する」:2025年2月4日閲覧
- World Economic Forum:「The Future of Jobs Report 2025」:2025年2月3日閲覧
X(旧ツイッター)やフェースブックのアカウントをフォロー頂くと最新記事を読み逃すことなく閲覧できます。
